How do AI Clinical Notes work? - A high level review for clinicians
by Chris Horwill, Founder
A simple Google of "Clinical Notes AI" will result in hundreds of possible companies, startups and software options world wide.
So how is it that all these companies are springing up so rapidly at the same time? And how do these tools work?
The answer is that the vast majority of these tools are all utilising the recently released Generative AI tools, such as the GPT-n series from OpenAI.
Let's take a high level look at the main components of these systems, referencing our partner company Cub Care's internal clinical note AI tool as an example.
Please note this article is aimed at clinicians not developers.
The Main Components
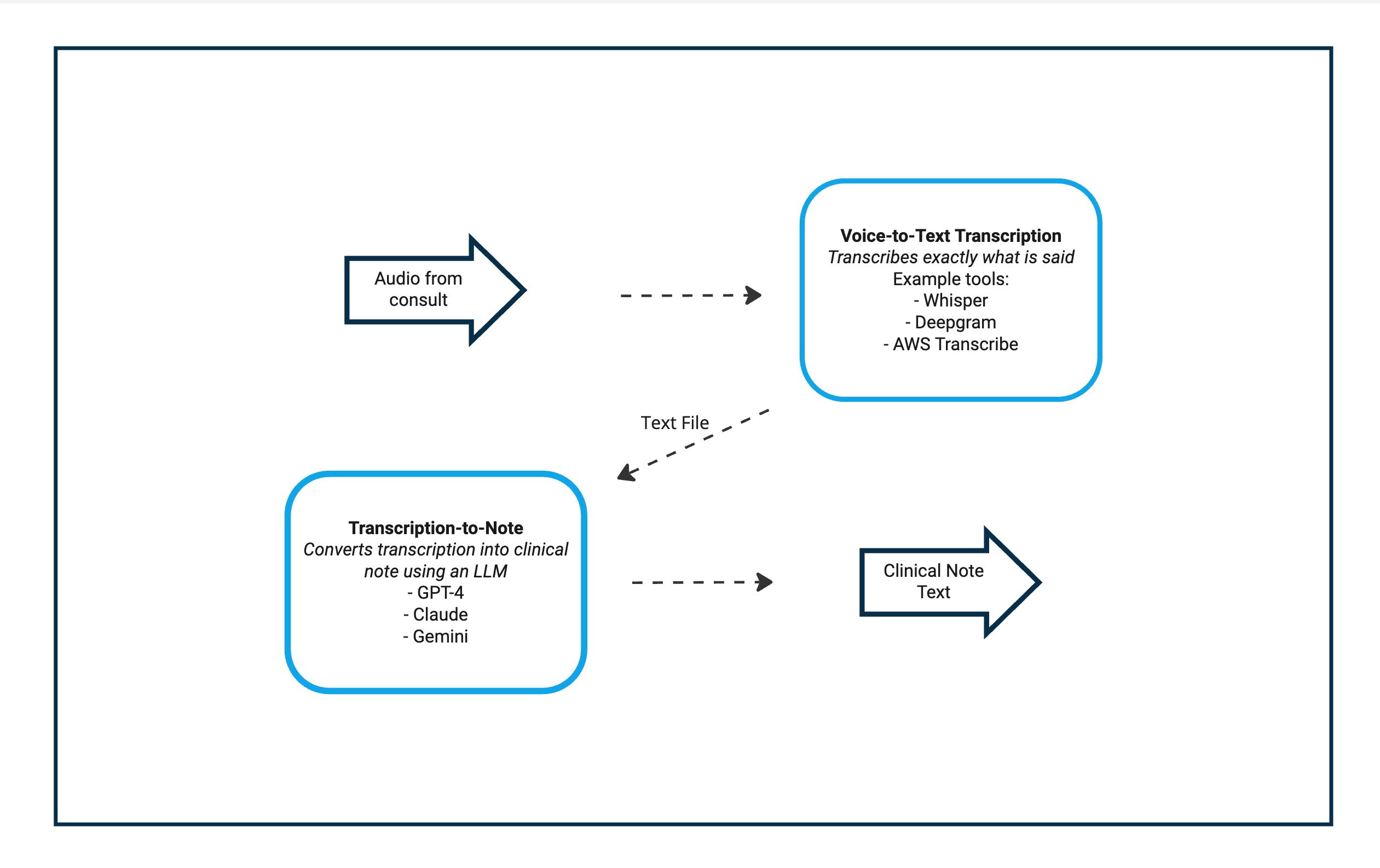
Figure 1. Simplified view of the 2 main components in the AI Clinical Notes pipeline.
There are 2 main components of most AI clinical note tools:
- Voice-to-Text transcription - these take audio from a consult and attempt to create a word for word transcription. This is similar to the tools that create subtitles on your TV. The output from this step is a text file.
- Transcript-to-Notes - The transcription text file is then fed to an Large Language Model (LLM), along with some other background info. The output of this is the clinical note.
While certain high level providers (such as Nuance) may create their own in-house solutions to these steps, for many smaller startups the technology for both of these core steps will usually be purchased off larger software companies such as Amazon, OpenAI and Microsoft.
As we'll go into below, the emergence and ease of availability of extremely powerful foundation LLMs means the results achievable from smaller players has become quite formidable, perhaps even superseding custom built solutions.
Voice-to-Text Step
The first step is to transcribe audio into text. This can be done using off-the-shelf tools / services. Some examples of common tools in this area are:
We did some internal testing on the above tools and found that most performed quite well.
For Cub Care's use cases, Whisper performed the best. Recognising most speech and removing unwanted "ums and ahs" with AWS Transcribe being the next best. Below is a comparison of Whisper vs Transcribe for interest.
Figure 3. OpenAI Whisper vs AWS Transcribe correction.
A strong considerations was that Whisper is not currently hosted in Australia by Microsoft or OpenAI (at least for the general public), so despite probably performing the best, it was ruled out (although we would like to move to it in the future). Amazon Transcribe is available for Australian hosting so we went with that.
So the output of this step is a text file (or "transcript") of the call.
What can go wrong in this step in any given system?
- Precision of audio to text conversion is low: We've found this can occur particularly around lesser known or "domain specific words". We've seen issues with "trade names" such as the brand "Cub Care", fortunately most times we can correct this in the next step with the LLM but occasionally this can cause issues. One option here is to run the LLM over the transcript twice with initial instructions to just clean up the text for missed words etc. We found for Cub Care that the AWS Transcribe and Whisper transcript have not regularly caused too many issues in this regard.
- Quality of audio file is poor: Garbage in, Garbage out. Poor microphone, large amount of ambient noise, multiple people talking can all lead to difficulty (though generally the tech is pretty good at filtering this). For Cub Care, as the calls are online, we are pulling directly from the WebRTC audio streams so this helps us both separate out the audio and generally get better quality.
- No Audio / loss of audio somewhere in technical chain: unfortunately the nature of IT is that there are near infinite combinations of hardware, software, operating system version. This can unfortunately lead to unforeseen technical issues specific to individual users.
Transcript-to-Notes Step
The next step is to change this verbatim transcript of the consult into a summarised clinical note or letter. This is done by utilising a large language model.
What has revolutionised the field of LLMs in recent years is the emergence of extremely large & powerful foundation models. These models are trained on huge data sets and can be applied to a wide variety of use cases.
The training of many of these larger models requires a huge amount of infrastructure and cost (in the hundreds of millions of dollars) and thus is being concentrated to a few key players, some examples are:
- OpenAI (partnered with Microsoft) - GPT series (ChatGPT, GPT4) Link
- Google - Gemini series Link
- Anthropic (partnered with Amazon) - Claude Series Link
Such is the power of these models, they do a pretty good job at a wide variety of tasks (Including summarising notes!) with minimal further adaption.
Even more conveniently despite the huge cost to train these models they are being made available relatively cheaply (~750,000 words of output cost US$30 OpenAI Pricing)
Of the LLM's we tried at the time, OpenAI's GPT-4 was the best performing and is currently the most popular model for many text based LLM tasks (noting that Gemini 1.5 and Claude 3.0 have recently been released and look quite impressive).
In simple terms, to use GPT-4 we buy access to this service on Microsoft Azure and pay Microsoft based on how much we use it (you can also buy direct from OpenAI).
GPT-4 has a few benefits - it is one of the best performing models out there, it is easily accessible through Microsoft Azure giving confidence on hosting and security and can be utilised from Microsoft Sydney servers. Specifically, that Azure OpenAI guarantees that sensitive user data will not be stored or used for training, and that the data remains in Australia.
We suspect many smaller Australian providers would be utilising a similar solution.
A quick note that data science is an extremely technical field, with many techniques available to optimise models and pipelines (RAG, fine-tuning, agents etc) for any given use case, so please be aware much of the above and following is a vast simplification, however for the purpose of this article, this basically works by:
- Prompt - Creating a section of text to send to an LLM. In most cases this text is written in "plain language" as if you were writing a message to a human, we normally try and ensure it has the following information
- Instruction - a specific task or instruction you want the model to perform - in this case it will be some variant of: "create a clinical note given this transcript"
- Context - external information or additional context that can steer the model to better responses - for example "this is structure of the notes we want to write", previous note examples of the tone, structure we want.
- Input Data - the input or question that we are interested to find a response for - for us the text of the transcription of the consult
- Output - the type or format of the output. - we often specify using Australian spelling, guide on tone "be brief"
- Send to LLM This prompt is then sent to an LLM (such as GPT-4)
- Output a text based output is created
In very simplified terms, we are essentially feeding the LLM some plain language written instructions on what to do and it is coming back to us with a text response.
As mentioned above we ultimately went with GPT-4, we also tested some Amazon solutions including the HealthScribe "all in one" option however GPT-4 was far superior.
Currently, Gemini or the AWS solutions are not hosted in Australia (at least to the general public, perhaps government or others have access) however Gemini 1.5 and Claude 3 look very promising.
What are some ways you improve the AI Clinical notes tech stack?
- Improve the prompt / provide more context: - this could be putting more context into the prompt through more explicit instructions, providing more and better examples of notes, specific exceptions or errors being noted to informed. There are technical options that enable large amounts of context to be added / certain info to be prioritised through something called RAG. Probably more excitedly the amount of context able to be added in upcoming models is huge, for example Gemini 1.5 has 1 million tokens or ~700,000 words able to be fed directly into the prompt! Clinical Notes AI tools will be utilising this extensively to feed examples or background info to the models to try and get the structure and tone for each individual use case as accurate possible etc.
- Fine-tuning of the LLM: - Whilst the initial training of an LLM is very expensive and time consuming, it is possible to fine-tune the base models with private data for specific use cases. OpenAI offers this service through an API. We haven't tried this option mostly due to the costs associated not just with training but also hosting if using it through Microsoft. We'd be interested to see if material improvements could be made using this method.
- Use a different LLM - in our testing we have found that this has been a large driver of performance. The new models coming out such as Gemini 1.5 and GPT-5 will improve performance against benchmarks and as flagged above enable very large amount of context to be given to the LLM. Although the processes are kept underwraps, I would suspect in the future (if not already) medical notes will become material parts of the training corpus.
What can go wrong in this step?
- Hallucinations Probably the most publicised issue for LLMs. In simple terms, sometimes they just make stuff up when it's not actually true! For medical notes, this could be making up something that didn't happen in the consult, or suggesting a management course that is not correct. Obviously this can be a major issue. You need to have a mechanism to ensure that the notes are reviewed before approved (and of course optimising your prompting etc to limit these errors)
- Too big inputs for context window Certain LLMs can have smaller context windows that mean for very long consults it misses certain details. There are technical ways to mitigate this and newer LLMs context window are getting larger and larger. GPT-4 Turbo is 128,000 tokens which is ~300 pages of text. We have not struck issues with our dictation because of that but haven't gone too much over an hour consult with our system.
Hope that helped! And reach out if you want to connect!
It's an extremely exciting time to be involved in data science. Hopefully this gave clinicians a high level understanding of how these tools work.
If you're interested in chatting further or working with us, please reach out!
Appendix: A Brief History of Time / Cloud Computing Providers
A very simplified summary of how most modern software is built and operated, to help us understand how the AI tools are implemented.
The vast majority of modern software utilises Cloud Computing Services as part of its architecture. Large providers such as: Amazon Web Services, Microsoft Azure and Google Cloud Platform enable on-demand delivery of IT resources over the internet with pay-as-you-go pricing.
So a company instead of buying, owning, and maintaining physical data centers and servers can access services such as computing power, storage, and databases, on an as-needed basis from a cloud provider.
This means that most software when accessed locally by a user (on a web browser or application) will communicate over the internet with these Cloud Computing Services to perform different tasks such as database access or business logic.
As these Cloud Computing providers have grown, as has the sophistication of their offering with the menu of services purchasable from AWS/Azure/GCP being incredibly large.
Importantly for this conversation, with the emergence of AI in recent years (specifically LLM) these services are now available directly from AWS, Azure, GCP enabling developers to purchase and deploy these securely as part of their own software offering.
Further, outside of these large cloud providers it has become common for software solutions to make their services available to other software companies via a specially focused integration method known as an API.
This lets a software solution integrate with another tool (for example payments through Stripe or Medipass), creating a relatively seamless experience for the user and meaning that the software company doesn't have to build this solution themselves.
Again for the purpose of this conversation, OpenAI and other AI providers offer access to their LLMs through an API.