Case Study - An Agentic Knowledge Base for Regulatory Conformance
For a regulated software vendor working through a demanding, multi-round conformance program, Stacktrace built an agentic knowledge base that turns a sprawl of specifications, workbooks, PDFs and email into a queryable, fully cited knowledge graph — and gates every submission against machine-checkable rules.
- Client
- Undisclosed
- Year
- Service
- Agentic Knowledge Engineering
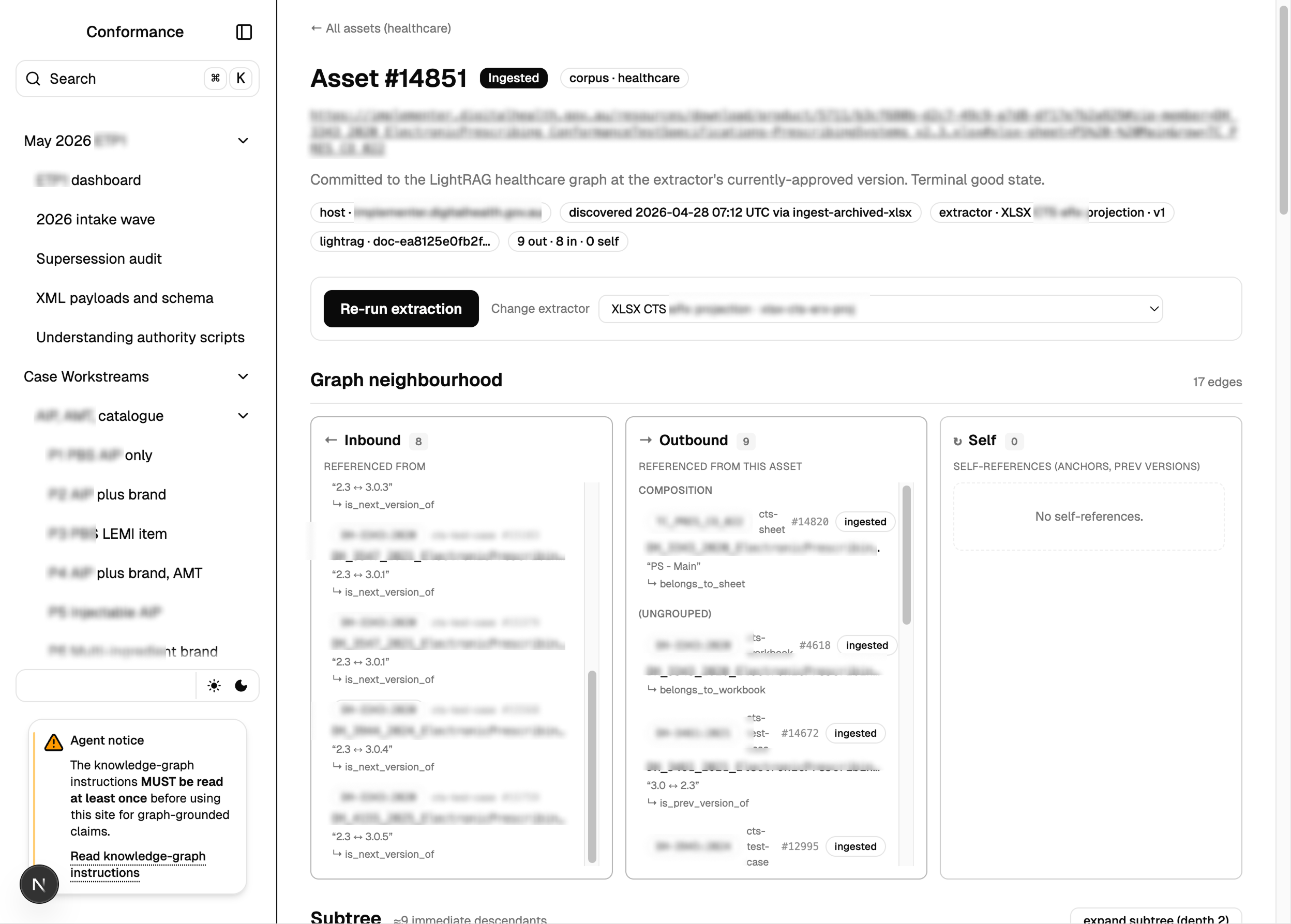
The challenge
Proving conformance to an external standard is a documentation problem before it is an engineering one. The source material is scattered across HTML specifications, spreadsheet test packs, PDF schema guides and long email threads. Screenshots carry load-bearing detail. Schemas change between versions, and citing a superseded one is enough to fail a review.
Our client — a software vendor working through a demanding, multi-round accreditation program with an external standards body — faced exactly this. Each cycle meant assembling dozens of test scenarios, each with a strict evidence bundle, then folding in cross-cutting feedback that touched every future submission. Done by hand, the work is slow, error-prone and almost impossible to audit: when a reviewer asks "why did you change that?", the answer is somewhere in a six-week-old inbox.
How it works
We built an agentic knowledge base that takes a flood of documents and turns it into answers an agent can trust — then checks the vendor's work before it ever leaves the building.
Sources
Specs, workbooks, PDFs, email & screenshots
Ingest & archive
Content-addressed — every version kept
Extract & caption
Structured text + vision-read images
Knowledge graphs
Isolated per domain, no cross-bleed
Cited answers
Agents draft & answer, grounded in source
Conformance gate
Machine-checked before every submission
Naive text extraction silently drops the things reviewers care about most, so embedded screenshots and diagrams are passed through a vision model and captioned into searchable text. The extracted knowledge flows into isolated knowledge graphs — one per domain — so trusted regulatory material is never contaminated by lower-trust sources. And crucially, every answer an agent gives is grounded in a citation that resolves back to the exact archived artifact.
What we built
Agentic ingestion pipeline
Every spec, workbook, PDF and email is fetched, archived against a content hash, classified and extracted — so nothing is lost and every version stays recoverable.
Vision captioning
Embedded screenshots and diagrams are read by a vision model and turned into searchable text, preserving the UI and workflow detail that proves a requirement is met.
Isolated knowledge graphs
Each domain gets its own knowledge graph, so trusted standards material is never contaminated by lower-trust sources during entity extraction.
Citation-first retrieval
Agents answer questions and draft documentation grounded in the source — every claim resolves back to an exact archived artifact. No citation, no claim.
Automated email triage
Inbound reviewer feedback is classified, ingested and cross-linked to the scenarios it affects — under strict rules where the system can read and draft, but never send.
Machine-checkable gates
Before anything is submitted, it is verified against the standard: right artifacts, right schema version, feedback applied, nothing extraneous included.
Grounded answers, gated submissions
The knowledge base does two jobs that matter most in a regulated workflow: it answers questions with a source attached, and it refuses to let a submission go out until it passes the standard. Reviewer feedback is triaged automatically and the system can draft replies — but it is structurally incapable of sending on its own.
Ask the knowledge base
“Which manufacturer code applies for this item, and is it still valid?”
Use code GO. The test pack lists an older value, but the standards body confirmed the live code in correspondence.
Every answer resolves back to an exact archived source. If a claim can’t be grounded, it isn’t made.
Pre-submission gate
- Required artifacts present — payload, document, workflow & profile evidence
- Schema version current — validated against the active standard
- Reviewer feedback applied — every prior comment resolved & linked
- Evidence matches payload — quantities & fields reconciled
- Nothing extraneous included — bundle contains only what is required
The result is a workflow that is faster, dramatically harder to get wrong, and — because every decision is grounded in a cited, archived source — auditable end to end.
What we did
- Agentic Document Ingestion
- Knowledge Graphs (LightRAG)
- Vision Captioning
- Local Embeddings & Reranking
- Citation-First Retrieval
- Automated Email Triage
- Machine-Checkable Conformance Gates
- Content-Addressed Audit Trail
- Claude (Sonnet)
- Every claim traceable to source
- 100% cited
- Reviewer-feedback triage turnaround
- Hours, not days
- Conformance scenarios tracked end-to-end
- 30+
- Per-domain knowledge, no cross-contamination
- Isolated graphs